EDDM E-Discovery Consulting combines capacity, speed, and flexibility while providing quality litigation support services. We have experienced consultants knowledgeable in the best ways to manage large-scale electronic discovery and document reviews. For our clients, this translates into fast-turnaround, lower costs and consistent results.
EDDM Consulting processes data from any source making it fully searchable. Our processing and database creation solutions are designed to simplify and streamline key processes in order to help clients manage time and decrease cost.
Native File databases are the best option when you want quicker access for review and a lower upfront cost. When processing for a Native review, we are able to:
- Extract and preserve metadata and text
- De-NIST
- De-duplicate
- Create hyperlinks to the native file location
- Keyword Searching
Each document can be reviewed in its native format (e.g. Word, Excel, Outlook, etc.) without altering the documents’ extracted information, hence avoiding spoliation. At EDDM Consulting, our aim is to reduce the amount of data by identifying, narrowing and de-duplicating files; creating a more manageable document set.
Because we provide quick access to the most useful information, your team will gain a decisive edge. With EDDM Consulting on your team, you will gain in-depth expertise and the most sophisticated technologies available; a combination that providing a true competitive edge. It’s a winning strategy that produces bottom-line results.
Processing and Analytics:
- Relativity (incl. Assisted Review)
- CloudNine Discovery
- Logickull
- Total Discovery
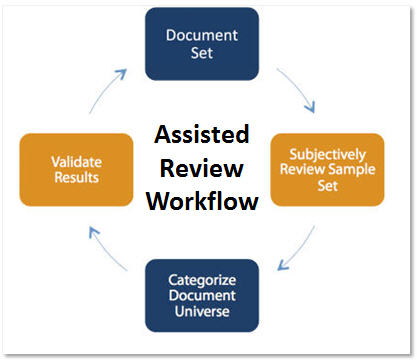
Predictive Coding (also referred to as “CAR” or “TAR”, computer or technology-assisted review) has become a buzzword in e-discovery, but when it comes to taking a close look at implementing it in your e-discovery processes, it can become a daunting topic to tackle.
Predictive coding provides accuracy, consistency, and transparency; while dramatically reducing time and cost of the first-pass review. Predictive coding works by “predicting” which electronic documents in a huge collection of documents are going to be responsive or non-responsive based on input from a human expert.
Either a lead, senior attorney or a subject matter expert; decides whether each randomly generated document is responsive or not. The sample of judged documents is processed to build a model of the language used in responsive and non-responsive documents; to predict the status of a new random sample of documents.